












Data Security & Privacy

Fast Delivery with High Accuracy

Cost Effective Pricing

Scalable Solution by Experts





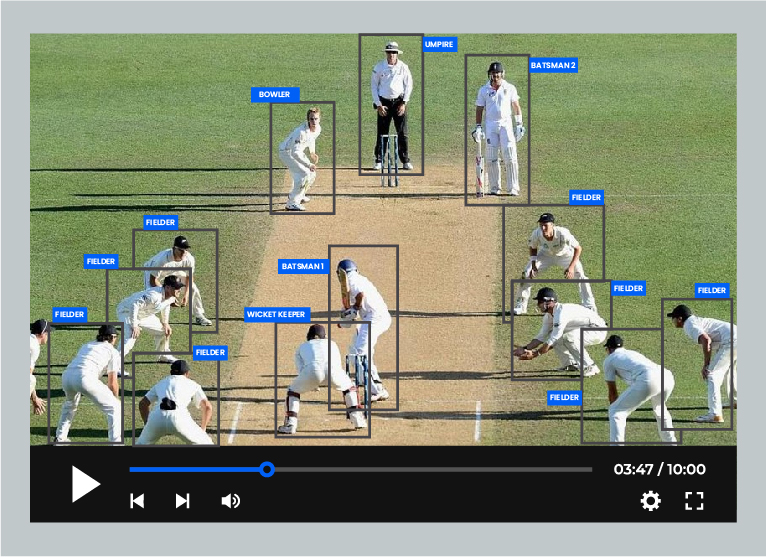
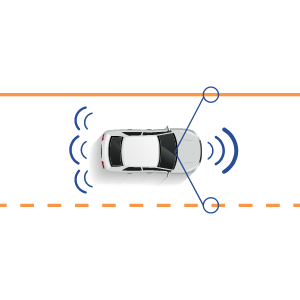
Video labeling object detection and position of an object determine the direction, path, and trajectory of the moving object and the surrounding things in the video data & video file. Such information is beneficial for autonomous driving features and autonomous machinery, among other computer vision and machine learning model.
Our in-house experts will carefully analyze your needs and overdeliver upon your data annotation and labelling expectations
A training dataset is a dataset that is accurately labeled based on the use case and is used to train the model. The training dataset is the initial data fed into the machine learning algorithms to train them to understand, process, and manipulate data and later perform the intended tasks or make predictions. The training dataset is crucial in determining the effectiveness of the AI model.
The process of annotating videos is more laborious and time-consuming than image annotation. It involves annotating all objects of interest in every frame in the video. Different video annotation methods include bounding boxes, polygon annotation, and semantic segmentation. The method selected to add the annotation labels depends on the video type and the annotated data’s intended use case.
Video annotation is adding tags or labels to video clips that are then used to train computer vision models to identify or detect objects. Video annotation, unlike image annotation, occurs at the frame level. The video is broken down into component frames. All objects of interest in each frame are annotated per the instructions.
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |