
Image Annotation and Labeling Services for Image Recognition





What is image annotation & labeling?
Image annotation task marks various target object in image data using specific image annotation tools and techniques to prepare the data to be understood and recognized by machine learning processes. Computer Vision models of AI-enabled technology need to be trained with highly accurate labeled images (also known as training data) to become autonomous.
What are the different types of image annotation?
2D and 3D bounding box
2D Bounding Box is a rectangular box drawn as boundaries around specific objects to highlight and label the objects.
3D Bounding Box Annotation adds the elements of height, width, and depth to the rectangular box by turning it into a cuboid allowing AI and Computer Vision models to understand the precise dimensions of the objects in the image datasets.


Polygon annotation
Annotation of irregular objects & images is best executed using Polygonal Labeling. It labels the exact shape of the irregular, asymmetrical and blurred things, thus improving image annotation accuracy.
Higher precision by Polygon Annotation improves the robustness of the Machine Learning process of the AI models.
Semantic and Panoptic segmentation
Computer Vision Semantic Segmentation and Panoptic Segmentation annotate different objects in the image pixel-level. In other words, each pixel of the image is labeled.
By annotating at a pixel level, background information is linked to the different objects in the images, which enriches the knowledge for AI & ML models.


Keypoint and Landmark annotation
Keypoint and Landmark labeling, also known as movement tracking annotation for computer vision, annotates independent points in the image and connects them to track movements and understand the shape of objects.
These are widely used to determine facial recognition, expressions, gestures, and emotions along with the movement and poses of the human body.
Polyline annotation
Polyline annotation determines the physical boundaries for the AI technology to work within. For example, Lane detection AI for autonomous vehicles and self-driving cars.
Using a combination of annotating lines and points, AI & ML Models learn the limits to which the technology should operate within.

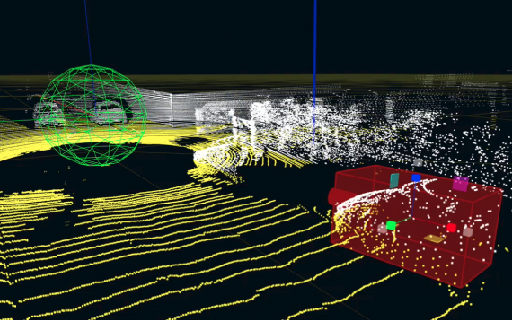
Annotation for LiDARs
Annotating the Point Cloud generated by 3D LIDAR sensor of technology with LiDAR capabilities requires unique skills due to the low resolution and higher technicalities and is a time-consuming process.
A combination of Bounding Box and Semantic Segmentation can achieve accuracy of up to 1cm, making it useful for navigation and determining the range and direction of movement.
Image annotation applications across industries






Worried about image annotation outsourcing? Annotation Labs is here to provide you the most secure and high quality Image annotation services.
Our beliefs behind each labeling task

Data Security & Privacy

Fast Delivery with High Accuracy

Cost Effective Pricing

Scalable Solution by Experts
- We are EU-GDPR compliant and SOC 2 Type 1 organization. Data security & privacy is non-negotiable for us
- Our scalable annotation solutions are driven by specialists with years of experience in AI & ML
- We deliver 3x faster and achieve 96%+ accuracy in our annotations and labeling
- Rated high than other image moderation service and image annotation companies
Annotation is essential as it helps machines understand different objects and data. Without data annotation, all data, including images, would be the same as machines that lack the inherent ability to differentiate anything in the real world. With data annotation, machines can recognize, identify and categorize different objects, making accurate predictions and results. It also helps machines learn to differentiate and manipulate other data inputs.
Data annotation involves marking, labels, or annotations on video frames, audio, text data, or images. Different methods of annotating data include bounding boxes, points, polygons, lines, or cuboids. The choice of how to annotate data depends on the intended use case as well as the effectiveness of the selected annotation method to capture the needed information.
Annotating data is the data that is collected to be used for annotation. Annotated data is used as the training data once correctly annotated. Annotating data differs from input data in that annotating data serves as the training data. In contrast, the term input data can refer to any data, including real-life data, used to test the effectiveness of an ML and AI model.
Deepfake works by training machine learning algorithms to generate data similar to the original data. Deepfake software then uses the generated data to perform the set tasks, such as replacing specified parts of an image with their image. Deepfake software programs must first be trained using vast data to create data based on autoencoders or generative adversarial networks (GAN).
Deepfaking an image is carried out by imposing or changing certain features in an image with your intended features. For instance, you can change an individual’s face in a photo with a different one to appear as if that is their real face. Creating a deepfake image can be achieved using deepfake applications or manipulating pixel image starting points.



