

Image bounding boxes, computer vision and image recognition are creating a seismic shift in how computers and real-world objects interact. One of the changes making inroads in most industries is computer vision object detection. However, not a new technology, the scope, sophistication, and applications of object detection in artificial intelligence and machine learning have expanded in recent years. Numerous applications in this area have been used in autonomous driving, security, and surveillance and in industries such as performing automated inspections of equipment and products.
What is object detection?
An object detection is the detection of real-world objects with the help of computers. In machine learning and deep learning processes, object detection is defined as the application of computer algorithms in computer vision machine learning models to locate and identify a real-world object in an image or a video. Once the objects are detected, they are then grouped according to their class or type in a process known as image classification. As such, for object detection to be regarded as successful, the computer algorithm must be able to locate, identify and predict the class of the said object correctly.
There could be more than one object or an array of objects in an image or a video. Programs must be able to identify each of the things as separate entities. The process through which these objects are identified separately is termed object localization and forms a bulk of object detection methods. However, these programs need ample training to learn what to detect and classify. Thanks to the bounding box and other image and video data labeling techniques, it is possible to annotate training data. Hence it is essential to choose the best data annotation companies which provide superior data labeling services.
Your updated annotation and labeling guide is ready
It is important to note that image recognition and object detection are similar with subtle differences. The AI & ML models assign a single label to the entire image or video data in image recognition. In comparison, the AI models label every classifiable object in the image or video data in object recognition. For this article, both processes can be considered similar and used interchangeably for ease of understanding.
What is a bounding Box?
As the name suggests, a bounding box is a rectangular or square box that bounds the object of interest and can be used to identify the relative position of the object of interest in a video or image. The bound thing is easy to locate and place and, therefore, can be easily distinguished from the rest of the objects.
The size of the bounding box is determined by the size and shape of the object to be bound. Based on the top-left and lower-right corner x and y-axis values, entities can choose the form of the bounding boxes. The most critical aspect of bounding box annotation is ensuring that the target object is entirely within the bounding box. The process of bounding a thing is usually simple. It involves drawing a box from one corner towards the other corner of the target object, ensuring that all surfaces of interest in the object are covered.
There are two significant types of bounding box annotation; 2D and 3D bounding annotation. The difference between these annotations is the level of detail that 3D bounding boxes can obtain. For a 2D bounding box annotation, only the length and width of the object are captured. However, 3D bounding box annotation takes this further by allowing the height of the subject thing to be captured, therefore giving more details about it.

How does bounding box annotation work?
Once the bounding box is drawn around an object, the big question remains how a machine can detect, identify and classify the said object concerning other things. In answering this question, it is essential to understand the process through which a technology-enabled machine goes through.
The work of annotating objects with bounding boxes is done by human image annotators who draw and label the bounding boxes. Usually, a different color is assigned to bounding boxes for each group of objects. For instance, if objects of interest are vehicles and humans, vehicle bounding boxes could have the color red and human ones color green. The annotated objects form the data used to train the algorithm how to classify and localize different objects in an image or a video. Object classification allows a machine to distinguish between two objects and categorize them appropriately. Object localization enables the algorithm to learn to detect where an object is. An algorithm learns to do both with bounding boxes, even in real-life applications. Read more about other image annotation services.
What are the applications of bounding boxes?
There is a growing number of areas where bounding box annotations continue to play a significant role in automating the process. As automation picks pace, the need for object detection and the potential for bounding box use cases is infinite. Let us look at some areas where bounding boxes are already in use today.
In autonomous cars
In recent years, interest in cars that can drive with any human intervention has picked pace. Several companies are in the process of developing such vehicles. Without human intervention, such vehicles need to be aware of their environment to identify all objects, including other vehicles, humans, traffic lights, or roadside barriers. Autonomous algorithms let the car know when to accelerate, stop or take a turn. That means that training datasets must train the algorithm to classify and localize all these objects using bounding box annotations.
In manufacturing industry
Today, manufacturing industries are no longer a collection of clanky heavy metals just turning and producing thunderous amounts of noise. Technology has made machinery highly efficient and computerized, with robots and intelligent machines able to localize and classify different products autonomously. With technology advancing daily, the sophistication in engineering is gearing towards more autonomous assembly, sorting, and quality control. That means an increased need for object detection and thus a need for bounding boxes to annotate training data.

In security and surveillance
It is perhaps the most widely known field in which object detection is applied. Growth in technology has made it possible to identify and track an individual even with a huge crowd. Commonly regarded as face detection and recognition, algorithms are trained to detect human faces. Increasingly content moderation is employed on social media sites such as Facebook, Twitter, and LinkedIn, which are used to detect and track criminals and persons of interest. For these algorithms to learn how to do that, bounding box annotated data is used to train them.
In automated CCTV
CCTVs work by recording everything and anything, which is inefficient and requires significant storage capacity. However, with object detection, CCTVs can be made efficient by automating them to record only particular detected objects.
In healthcare and medicine
Advancement in technology means it is possible to detect anomalies in human tissues without putting one under the knife. Commonly referred to as medical imaging, the software is being used to aid medical practitioners in accurately and rapidly analyzing medical images to make diagnoses and initiate treatment plans before conditions advance. One area where medical object detection is used widely is detecting anatomical deformities in the human heart.
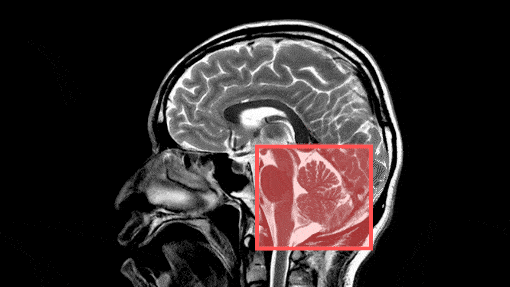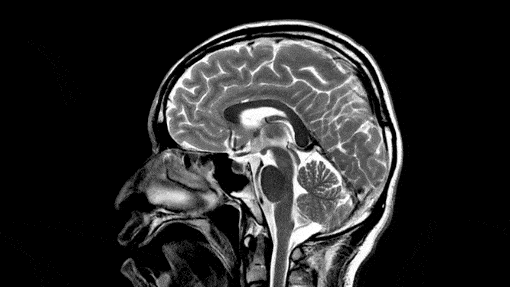
In robotics
Automation of human routines is catching up in most industries. In some sectors, such as hospitality and banking, some operations are performed by robots. At home, robots are used to perform some functions such as cleaning. The robots need to detect other objects and react accordingly.
The list of areas where object detection is in use currently or will be in use in the future is endless. As humans shift towards automation, it is expected that more use cases for bounding boxes and other image annotation applications will rise. Anything with a pattern that can be automated is another potential use case for bounding boxes.
What is needed to annotate using bounding boxes?
Unlike other annotation methods, which are considered complicated, image recognition bounding box annotation is straightforward. It does not need much effort, nor does it need high-level skills. Anyone with slight computer skills and high accuracy can become an annotator. Accuracy is critical in training AI models. Inaccurate annotated data results in wrong datasets, an express recipe for a disastrous computer vision project.
For an aspiring data annotator, accuracy should be part of the commitment. You also need to have a computer or a laptop, but if you work for a company, most likely, they will provide you with a computer. But for image annotation tool and video bounding box annotation tool parts, this is one of the best image annotation service providers you can avail to annotate image and video datasets using bounding boxes. Once hired, they provide a meticulous and methodical plan to annotate objects as per your guidelines.
It is important to note that the requirements for each project will vary from one customer to another, even within bounding box annotations. Hence precision, accuracy and data security is paramount. As the drive toward automation gains momentum, it is expected that the need for image annotation and bounding boxes will increase significantly.



