

Technology has become a centerpiece of human civilization. In recent years, humans have achieved significant technological breakthroughs that effectively shape how they live and interact with the outside world. One critical technological marvel has been artificial intelligence (AI) and machine learning (ML) advancements. From Netflix to Apple Siri, AI and ML have been so inherently embedded in our daily lives that it would be impossible to imagine a life without them. Conspiracy theories project that AI and ML might soon replace or surpass human intelligence.
However, it is essential to note that these fields are inherently based on the skills of humans who can develop advanced tools in AI & ML and create datasets for training AI & ML models. They require the guidance of humans to build the logic and rationale for comprehending various objects of the natural world environment. The process often involves creating guides akin to cheat sheets which guide the machine on how to interpret each object they interact with. The bedrock of creating these cheat sheets starts from data annotation and labelling services. Once data is annotated or labeled, the ML models are put through vigorous training using a large volume of annotated data. With enough training over a period of time, the machines learn how to interpret objects and thus gain artificial intelligence that mimics human intelligence.
One prominent method of annotating data is image segmentation. Image segmentation has become profoundly important, especially in the wake of growing computer vision-based tasks for machines, also understood as making machines interpret the surroundings as humans do. Computer vision requires that machines identify objects, recognize their shapes, predict the relative position and direction, and make suitable decisions based on the prevailing object condition. Without image segmentation, this is unachievable.
What is image segmentation?
Image segmentation allows machines to use computer vision to detect, recognize and classify objects. To enable computer vision, images are annotated or labelled at the pixel level of images. Each object is divided into different segments, called an image object. A computer vision application can differentiate between various image objects in an image through this division. Broadly, image segmentation is classified into semantic segmentation, instance segmentation, and panoptic segmentation. All of them focus on pixel-level image annotation. This article focuses on semantic segmentation and why it is crucial.
What is semantic segmentation?
Semantic segmentation involves labeling similar objects in an image based on properties such as size and their location. In essence, semantic segmentation consists of associating each pixel of the image with a class label or defined categories. Simply put, every pixel in the image corresponds with a predefined object class. These classes usually represent real-world objects such as cars, persons, flowers, etc.
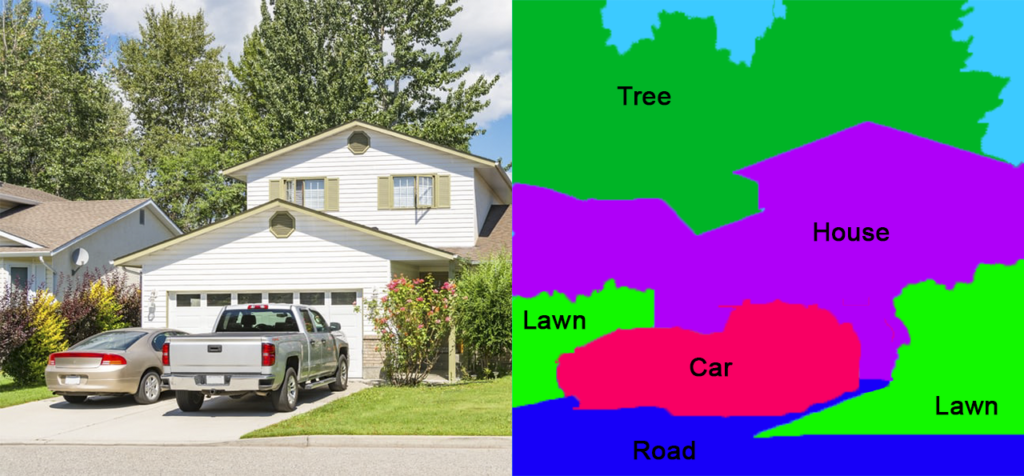
Semantic segmentation training works at a high level in which images and videos are not differentiated into different instances of the particular identified object. In images and video semantic segmentation, multiple objects of the same category or class are treated as one entity. For example, an image with various persons is segmented and labelled as a person without going into details about whether they are the first instance of a person in the image. Each category of annotated objects is represented by a different colour, making it easy for ML models to differentiate between different object categories.
Semantic segmentation vs instance segmentation
The semantic segmentation tool considers different objects within a single category as part of the same entity. Graphically, all objects in the same category are annotated using the same colour.
Let’s take an example of an image of some animals sitting on a couch. In this image, all animals will be labeled as one entity using the same colour. At the same time, the sofa and other background elements will be considered as another entity and annotated using another colour.
Instance segmentation annotates on a deeper level where it identifies different objects individually and labels them separately.
To continue with the above example, each animal will be considered as different objects and labeled using a different colour hence distinguishing between a cat and a dog. Similarly, each background element will also be regarded as a separate object; thus, a couch will be labeled separately from the wall and the floor.
In conclusion, instance segmentation achieves higher accuracy for computer vision datasets by adding another layer of detail to the image and video datasets. Among the best data annotation services include

Where are semantic segmentation models used?
Numerous benefits associated with semantic segmentation training give rise to its importance. Due to semantic label’s ability to annotate an image at the pixel level, semantic segmentation is preferred for computer vision tasks due to its higher accuracy than other annotation tools. Let us look at some of the semantic segmentation applications and why they are essential in these applications.
Deep learning
Before the advancements in computer vision, image processing was based on grey-level segmentation. However, this was problematic as it was not robust and could not handle complex classes of objects. The challenge is, however, overcome using semantic segmentation, which is powerful and allows statistical modelling methods to make predictions about the objects in the image datasets.
In deep learning, semantic segmentation is crucial in allowing fully hierarchical-stacked neural networks to make structured predictions with unprecedented accuracy and high resolution. The high-resolution map is created entirely by hierarchical-stacked neural networks that transform each pixel. It allows machines to understand objects of random sizes and shapes better. Semantic segmentation is, therefore, crucial in advancing deep learning in image recognition.
Autonomous self driving vehicles
Autonomous cars are becoming a reality, which would have been a wild dream some years back. The central concept behind self-driving cars is their ability to detect and identify various objects on their path and make predictions and relevant decisions. Therefore, they must be able to know what each object they interact with is and how that affects their environment. Semantic segmentation plays a vital role in this process. During the training of such autonomous cars, images of traffic and roads are semantically segmented, and all different objects are put into different categories. That makes it easy for ML modelling to identify the other class objects in image and video datasets.
Since semantic segmentation labels images at a pixel level, it provides enough information for the model to make predictions with high accuracy. Further, object detection and classification for autonomous vehicles work at the class level, not at the instance level. Thus semantic segmentation is more applicable for autonomous cars than other forms of image segmentation.
Medical and healthcare scans
In the medical field, anomalies in human cells can be detected and differentiated using semantic segmentation. Tumours and abscesses result in defective cells, which can be captured through medical imaging techniques such as MRI and X-Ray. For doctors, identifying the regions or cells with anomalies is more critical as compared to knowing the unique number of instances of irregularities. Medical images use semantic segmentation to label areas where abnormalities are detected, differentiating them from regular healthy areas.
Satellite imaging
Satellites have been a significant achievement in the history of humanity. Satellites are essential in different areas and have been critical to our daily lives. Numerous satellites are designed to carry out specific tasks such as monitoring ocean levels, detecting oil spillage, mapping out different areas, and monitoring the health of crops in the fields. As such, satellites need a mechanism to detect and differentiate the other objects they come across.
Many satellites, especially those that work on detecting levels of certain elements, need the means to show the difference when the said element or object is present and when it is not. Semantic segmentation makes this differentiation possible by allowing instances of things to be identified and classified into different categories easily. For example, regular water will be considered quite clear for a satellite monitoring oil spillage, while oil spillage will be darker. The satellite imagery can capture this through semantic segmentation, allowing for a straightforward interpretation of images and taking the necessary action.
Fashion and retail industry
Image semantic segmentation has become an essential part of the fashion industry. It allows easy grouping of similar clothing items, making it easy for fashion retailers to make recommendations for their clients. For instance, semantic segmentation is accessible to group trousers together based on their shape. The grouping means that even on online selling sites, it is easier for AI algorithms to identify different clothing and make proper recommendations based on the customer search history or relevance.
Drone technology
Drone technology has advanced tremendously in recent years. Drones are finding applications in different areas and breaking into fields where we could not have thought of their application. In recent years, drones have become essential in farming, harvesting, mining, construction, and warfare. The drones work by detecting specified objects and making appropriate decisions. For them to operate, they need to be able to see and evade obstructions.
Video semantic segmentation is vital as it helps map possible objects in a drone’s route. It works by semantically segmenting all possible things the drone might encounter and putting them into different categories. The drone ML model is then trained to identify and categorize these objects and what to do if they come across such. Since this process only requires high-level detection and classification, other segmentation methods are not appropriate, leaving semantic segmentation as the most suitable, thereby making it essential.
Closing thoughts
Semantic segmentation annotation services plays a vital role in the field of computer vision. It is most preferred due to its simplicity and high accuracy. Its ability to identify objects in an image in real life without going into deeper details makes it applicable in instances where information is not essential. Semantic segmentation also becomes helpful in deep learning, where images require in-depth analysis. It allows for image pixel-by-pixel transformation, which is necessary when achieving high accuracy in deep understanding. Besides, it can be used with various techniques, making it more suitable for deep learning. All said and done, semantic segmentation has its shortcomings, especially when we need granular level information. It should therefore be used based on the need and applicability basis.


