

We hear common buzzwords about machine learning, artificial intelligence, and deep learning. The terms have recently become mainstream, driven by the growing daily applications implementing these technologies. Despite the widespread implementation of such technologies, these terminologies may sound intimidating and frustrating. This article will dive deeply into machine learning to help you understand what it is and how it is implemented. Let us get right into it.
What is Machine Learning?
Machine learning, or simply called a ml model, is the process of teaching computer systems to correctly and accurately make predictions based on input data. The type of prediction varies from one situation to another based on the type of input data. In computer science, ML is defined as a branch of computer science and artificial intelligence focusing on using algorithms and data to imitate human ways of learning where accuracy is achieved gradually over time.
Machine learning differs from traditional computer systems because traditional software relies on human-written code to differentiate between objects. However, in ML, the machine is taught to discern between different products using large amounts of data. Therefore, while traditional software relies on code instructions to make a prediction, ML systems use the knowledge gained to make the predictions.
Machine Learning vs. Artificial Intelligence
Machine Learning has been at the centre stage recently, prompting many to wonder whether ML and Artificial Intelligence are the same. Put simply, machine learning is one of the methods that can be used to achieve artificial intelligence in a machine. The history of AI and ML has significantly been intertwined since the 1950s when the first intelligent machines started making a debut. At the time, AI was defined as machines capable of performing tasks without human inputs. Despite advancements in technology, the definition has remained relatively the same.
As mentioned, ML is just one way of achieving AI. There are other methods, such as evolutionary computation. In evolutionary computation, algorithms are programmed to learn and improve themselves by undergoing mutations. As such, both evolutionary computation and ML are considered branches under AI.
What are the different types of models in Machine Learning?
Having understood that ML is a branch of AI, let us now focus on understanding what it entails by looking at the main types of ML.
Supervised Learning
Supervised learning is one of the types of ML where machines are taught using examples. In supervised learning, a large amount of annotated data is used – a quick guide on data labeling will explain better. For instance, large volumes of the image are used where each image is labelled to show what the objects in the image correspond to. Through continuous training, the machine learns to recognize the number or cluster of pixels and shapes associated with specific objects. That way, they can identify such things in the future by inferring from the knowledge gained during their training.
Supervised learning is tedious and time-consuming as it requires the machine to be exposed to millions of annotated and labelled images. Obtaining these machine learning datasets is a laborious process. While some open source datasets, such as from Google, exist, some ML models require specific datasets and are not available online. That means the datasets will have to be curated from scratch by accurately annotating the data, which is a laborious process. In such circumstances, one has to outsource the experts in the data labelling process to achieve a fast turnaround.
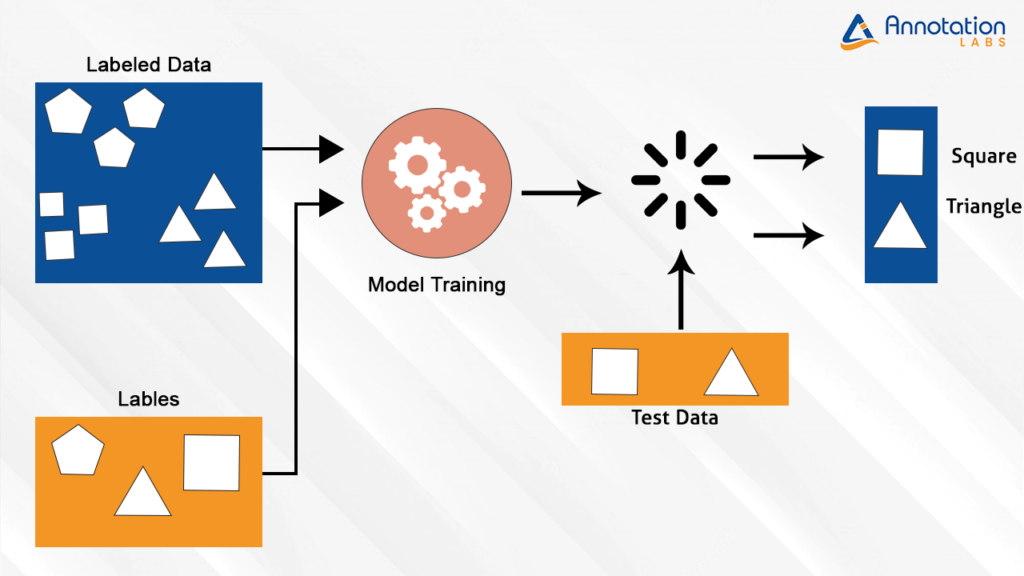
Unsupervised Learning
Unsupervised learning works in contrast to supervised learning. It works by having the algorithms identify and learn patterns in large machine learning data sets, use the identified patterns from earlier processes to recognize and comprehend similarities between different data, and split the data into categories based on the recognized similarities.
Unlike supervised learning, which is data type specific, unsupervised learning works by simply looking for similarities within a machine learning dataset and grouping it into the same category.
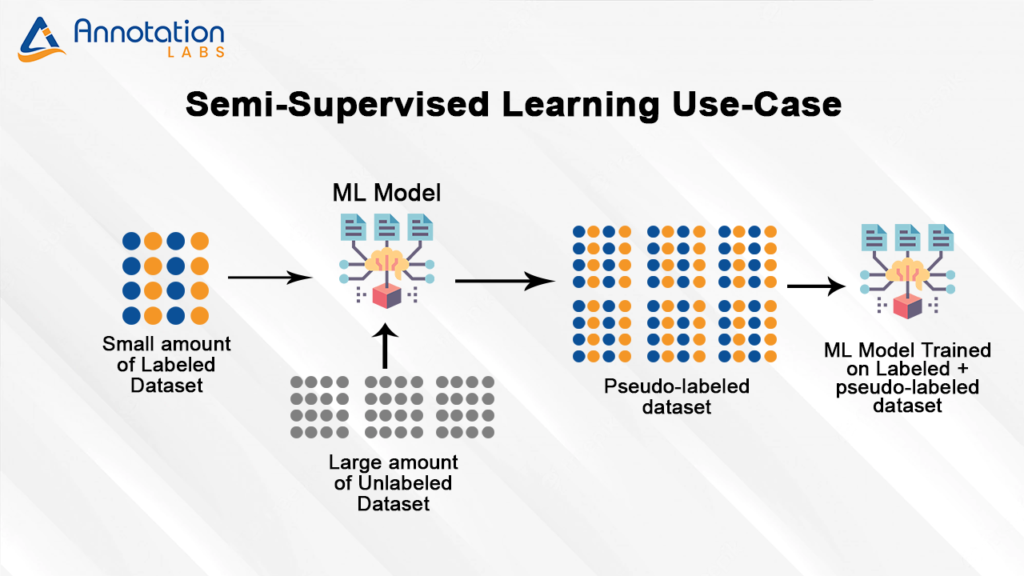
Semi-supervised Learning
As previously mentioned, supervised learning is data-intensive, which makes it an arduous, time-consuming exercise. However, the rise of semi-supervised learning is promising to change this. Semi-supervised learning mixes both supervised and unsupervised learning. In this method, a small amount of accurately annotated data is used together with large amounts of unlabeled data to train the machine learning models. The labelled data is first used to train the model partially. The partially trained model is then used to predict and label the large volume of unlabeled data, helping the model learn in this process. The process is called pseudo-labelling.
Understand why high accuracy of training data, also known as labeled data, matters a lot.
Recent advances in this area have seen the development of Generative Adversarial Networks or GAN. In GAN, machines use already labeled data to generate new data that can be used to train ML models. It is projected that in the future, advances in semi-supervised learning will necessitate the need for more computation power and not vast volumes of data.
Another branch of machine learning is Active Learning. A subset of semi-supervised machine learning, active learning is a process where an algorithm proactively decides which datasets it wants to train and learn from. This process speeds up the machine learning process, especially when the amount of labelled or annotated is insignificant, and the data science engineers are dealing with limited resources such as computational power and a low budget for data annotation.
Understanding Reinforcement Learning
Reinforcement learning is the process through which a machine learns by performing a task repetitively. During the process of completing the tasks repeatedly, the machine learns to associate particular actions with particular outcomes, thereby gaining the ability to make predictions when faced with similar scenarios. Reinforcement learning operates the same for both humans and machines. In humans, for instance, individuals become good chess players by continuously practising and knowing what moves to make based on the opponent’s piece movements. Similarly, through reinforcement learning, the chess-playing machine continuously learns by playing against other computers or humans to make correct predictions every time an opponent makes a move. For computers, reinforcement learning works by enabling the ML model to make predictions that optimize the progress towards achieving the desired outcome.
How to train a Machine Learning Model using the Supervised Learning method?
Before discussing how machine learning (ML) models are trained, let us first define an ML model. An ML model is a mathematical function capable of repeatedly modifying its operation until accurate prediction. The ML algorithm makes adjustments every time new data is input to ensure that the resulting output is correct.
As you might have deduced from the above definition, ML models are trained using data. Therefore, before training the models, you must first collect the data. The collected data is then sorted, errors corrected, and normalised in a process called data cleaning. The clean data is then annotated to help the machine identify what is contained in the data and to enable it to interpret the raw data. The clean and annotated data is then used as the input to train the model. During training, the model learns to tweak its algorithm, understand the data, and make a correct prediction.
What are the other methods of training Machine Learning models?
Simple Model
Uses logistic regression to classify data. It is straightforward and often more suited to carrying out binary classification.
Support Vector Machines (SVM)
SVM uses regression to classify data and make predictions. It is more advanced and is capable of putting data into separate classes, even with garbled data.
How to evaluate the accuracy of Machine Learning Model?
Upon complete training of an ML model, the next phase is its evaluation. Evaluation is done using the unused data left during the training process. Evaluation helps to gauge the performance of the model in real-world settings. Typically, at least 70% of the labeled data will be used to train the data, and around 30% will be used to evaluate and adjust the model. During the evaluation, various parameters are adjusted through fine-tuning to optimise the model and increase the accuracy of the output.
Fine-tuning during evaluation is critical as it helps solve major ML models’ problems, such as overfitting. Overfitting of ML models is a scenario in which models produce accurate results when original training data is used as input, but the same accuracy is not achieved for a new data set. In reverse, underfitting occurs when the model cannot achieve the same accuracy when training data is used. Underfitting is a more severe problem than overfitting as it compromises the general accuracy of the model. It is important to note that understanding the use of the ML model is crucial to proper training and evaluation of the model. Having enough subject matter knowledge makes it possible to understand what data affects accuracy in different situations.
What is cross validation of Machine Learning models?
Given the complexity of processes in Machine Learning models, there is a constant need to test and validate these models for their robustness. Cross-validation is one such process to validate the efficiency of an ML model. In this technique, a subset of the training dataset is set as a reserve and not used in the training dataset. Before deployment, the training ML model is tested on the reserve dataset for accuracy.
Cross-validation consists of 3 simple steps:
- Set aside some sample dataset, also called reserve dataset
- Train the ML model using the remaining training dataset
- Test the efficiency of ML models using the reserve dataset
What are Neural Networks? (Neural Networks vs. Machine Learning)
Neural networks are the foundation or the bedrock in the field of ML. Neural networks in ML are inspired by the human network of neurons which work together to perform various functions. In the human brain, the neurons form a network, where one neuron feeds data to the other. That means one neuron’s output is the input for the next layer of neurons. Similarly, in ML, neural networks are designed into layers where each layer carries out some tasks that contribute to the overall output.
For instance, the first layer in a neural network could recognize patterns, the next shape, and the last one classifies the object. The interlinking between the various neural network layers allows for incrementing or decreasing the significance assigned to each layer. After every output, the system evaluates how close or far the output is from the desired outcome and adjusts the weight of significance assigned to each neural layer.
What is Deep Learning? (Deep Learning vs. Machine Learning)
Deep Learning is a subset of ML that improves the concept of neural networks. In deep learning, several neural network layers are stacked in a hierarchy of increasing complexity. Statistical output from each layer of the neural network becomes the input for the following neural network layer in the stacked hierarchy. A significant number of neural network layers coin the word “deep” in “deep learning”.
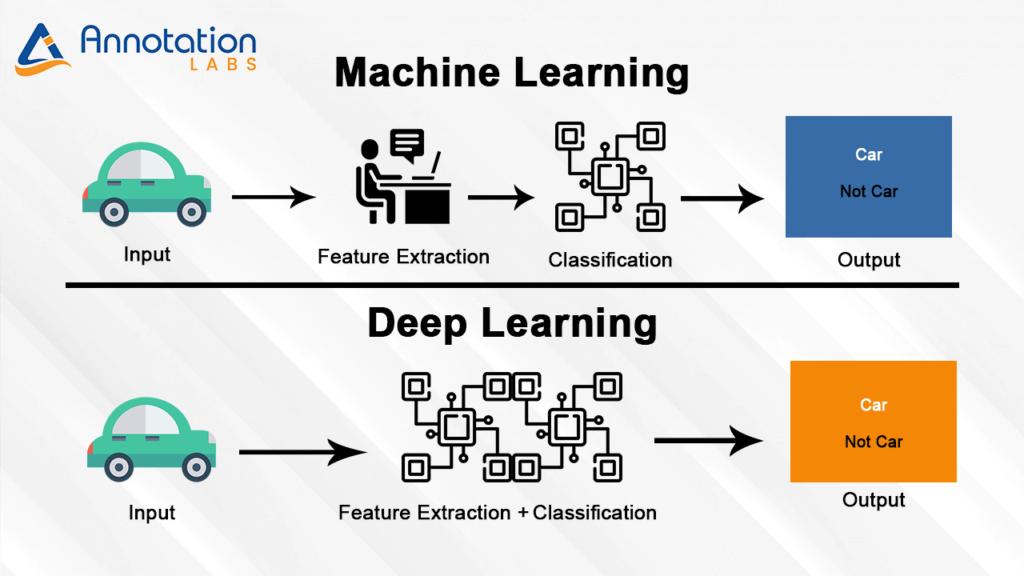
So how is Deep Learning different from the supervised learning of ML models? In supervised learning, a data scientist must be cautious in telling the model what objects or features the model should be looking for. Hence, the model’s success depends mainly on the data scientist’s and machine learning engineer’s skill sets to accurately define the objects or features that the model should identify. The advantage of deep learning ML models is that the model determines the objects or features by itself without supervision, making Deep Learning models more accurate.
The advancements in deep learning have significantly propelled ML advancement allowing for applications such as speech recognition and computer vision.
Why is Machine Learning suddenly so important?
As earlier mentioned, ML is not a new field and has been around since the 1950s. However, recent years have seen an explosion of interest in this field. The current boom is driven by several developments, including breakthroughs in deep learning. Deep Learning, in particular, has generated a lot of interest in voice and language recognition prompting the growth of interest in ML.
The parallel growth and improvement in computing and processing capabilities of computers have also significantly contributed to the boom in machine learning. Modern GPUs allow the clustering and formation of ML powerhouses. These have become easily accessible online, allowing anyone with a computer and internet access to train their ML model. Companies are investing in special hardware for running and training ML models. This hardware accelerates the rate of building and training ML models. Companies investing heavily in specialized hardware include Google, which is making the Tensor Processing Unit.
Besides, the advances in ML hardware are also prompting refining frameworks for ML software. These changes have allowed people to run ML models on their mobile phones and computer. The effect has been the pervasive increase in the global number of ML models that are in training.
What are the day to day applications of Machine Learning models?
Today, ML has become the mainstay of our daily lives. ML has become the cornerstone of nearly all stems, including the internet. Talking of the internet, all our favourite products are recommended using ML algorithms. Similarly, search engines such as Google uses multiple ML algorithms to understand your search queries and know the result to give you back. Further, ML algorithms are used to personalize our search results to ensure that we do not get bombarded with unwanted recommendations.
Mailing service providers such as Gmail also use ML models to ensure you do not end up with billions of rogue spam emails. However, for many people, one example of an ML model that resonates well is virtual assistants such as Alexa from Amazon, Siri by Apple, and Google Assistant. These systems rely heavily on ML to recognize the voice and their ability to understand and process natural language. Further, several ML models are used to give feedback to your queries on such systems.
In essence, the application of ML is widespread. It has found use in various areas, including self-driving cars, drones, and medicine. ML models are used in gene sequencing and drug manufacturing to test different drug molecules’ effectiveness. ML is also making progress in the delivery field, where companies such as amazon are making progress in drone deliveries. Such drones rely on computer vision which ML models achieve. Simply the uses of ML are unlimited.
Closing thoughts on Machine Learning
Advances in ML have many worried that it will be the undoing of humans. Many fear ML is taking their jobs and that we might need human labour soon. However, nothing can be further from the truth. The indisputable fact is that humans, regardless of the advances in ML, will always have a role to play in the world. Therefore it is impossible to eliminate the need for human labour. Besides, the fear that ML may lead to apocalyptic consequences if the machines surpass humans’ intelligence is impossible to confirm. At times, it is easier to wait and see rather than predict doom, yet we are only beginning to see the benefits of ML.



